Data Set Naming Convention
Within Getech, we decided to change our naming convention for all Globe data sets to a new 25 alphanumeric code. This facilitated the building of sophisticated systems and tools to help query and maintain the data for our internal and external clients. Below are explanations of the original and new naming conventions.
Original Naming Convention
The way we used to name our data sets did not allow for consistent, unique, predictable and logical naming. This caused various problems: with the amount of data we produced and made regular additions to, we were beginning to find creating unique names a difficult task; there was also an increasing risk that we would be forced to break our naming convention, which would lead to the breakdown of the whole naming process.
The names of data sets were held in Feature Data Sets, which provided scope for naming similar groups of data that were differentiated by timeslice (see Figure 1).
It had worked for us but, by its very nature, it was hard to programmatically ascertain names of data sets based on this naming convention; therefore, the decision was made to break down each unique part of the data set name and perhaps add extra elements to it in order to uniquely describe it. There are five major elements that can be used to describe a data set uniquely:
- Data theme (e.g. rivers, gross depositional environments, terranes, structures, etc.)
- Timeslice information
- Scale (e.g. 1:20M, 1:10M, etc.)
- Plate model
- Projection system
New Naming Convention
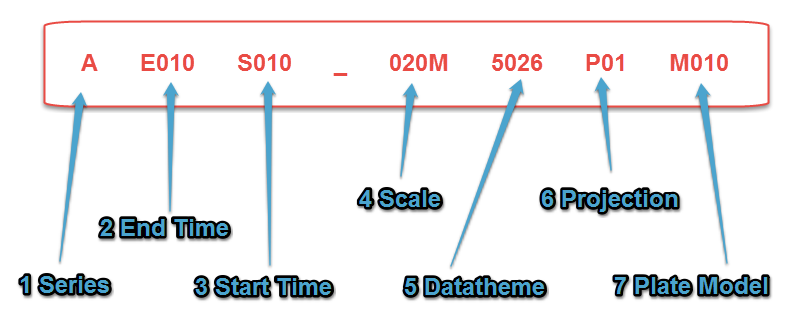
Figure 2 is an example of the new naming convention that we have adopted. Every part of the code has a meaning and can be deciphered in conjunction with lookup tables to reveal the exact meaning of the data. This particular code describes a rivers data set that was constructed in the Pleistocene timeslice at 1:20M scale and in a WGS84 projection system using Global Plate Model v.1. Its original name using the old naming convention was G_RIVERS_20M_CZ_PLEI_M1_0.
- Series: This is the first issue of data, and at present, this is marked with an 'A'.
- End Time: This is the timeslice that indicates the current palaeoposition of the data, whether rotated back in time (reconstructed), forward in time (deconstructed) or created in the specified timeslice (constructed). The end time code always starts with an 'E' and ends with three numbers, e.g. Aptian palaeoenvironments would have an end time code of 'E260'.
- Start Time: This is the timeslice that the data originate from, commonly 'S000' for Present Day. However, for data 'deconstructed' from their palaeoposition to Present Day, the start time code will be whatever is relevant to the starting timeslice. The start time code always starts with an 'S' and ends with three numbers, e.g. Aptian palaeoenvironments 'deconstructed' to Present Day would have a start time code of 'S260'. N.B. When the end time and start time codes are the same, this indicates that the data have been 'constructed' in the specified timeslice. Typically, this would be palaeogeography data sets that have been 'constructed' on basemaps consisting of 'reconstructed' Present Day data, but this also applies to Present Day data sets that remain in Present Day position, e.g. Aptian palaeoenvironments would have an end time code of 'E260' and a start time code of 'S260'. Likewise, Present Day data sets would have an end time code of 'E000' and a start time code of 'S000'.
- Scale: This is the scale of the data, commonly 1:20M. This code always starts with three numbers and ends with either an 'M' or a 'K'.
- Data Theme: This is a general theme describing the data, e.g. structures, rivers, data points, drainage basins, etc. This code is always made up of four numbers.
- Projection: This is usually WGS84, but could be a North Pole or South Pole projection. The projection code always starts with a 'P' and ends with two numbers to indicate the projection system.
- Plate Model: This indicates the plate model to which the data were created. This code always begins with an 'M' and ends with three numbers.